안녕하십니까 오늘은 논문 정리를 진행하려고 합니다. 직접 읽고 제가 생각한 바를 적는 공간이라 틀린 부분이 있을 수도 있습니다. 궁금한 점이 있거나 수정해야 할 부분이 있으면 댓글 부탁드립니다.
처음으로 논문정리할 논문은 mobilenetV2: Inverted Residuals and Linear Bottlenecks입니다!! 시작하겠습니다
1. Introduction
요약하자면 이 논문에서는 새로운 네트워크 아키텍쳐를 소개할 것이다. 이는 모바일이나 리소스가 제약된 환경을 위한 것이다. 그리고 같은 정확도를 가지면서도 연산수를 크게 줄이고 사용되는 메모리를 줄여준다. 정도입니다.
2. Related Work
이 논문 출시 유명했던 네트워크에대해서 언급하고 이들은 하나의 단점이 있다면서 바로 네트워크가 매우 복잡하다는 것이다. 그러면서 이 mobilenetV2는 가능한 매우 간단한 네트워크 디자인을 추구했다는 식으로 설명되어있고 mobilenetV1을 기반이며 mobilenetV1의 심플함을 가지고 있으며 어떠한 특별한 연산자를 요구하지 않는다.라고 적혀있습니다.
3. Preliminaries, discussion and intuition
3.1 Depthwis Separable Convolutions
역시 Depthwise Separable Convolutions부터 설명을 시작합니다. mobilenetV1에서 나온 연산량을 확 줄여준 convolution 이기 때문이다. 이는 mobilenetV1때 나왔지만 mobilenetV2에도 사용이 되어 간단하게 설명이 진행됩니다.
먼저 기존의 Convolution의 경우에는 총 computational cost가 H * W * Di * Dj * k * k
여기서 사용되는 Depthwise Separable Convolution cost는 H * W * Di * (k*k + Dj)
따라서 mobilenetV2인 경우에 필터의 폭과 높이가 3x3이기 때문에 이를 적용하면 대략적으로 8~9배 적은 연산량을 가지고 convolution을 진행하게 된다는 이점이 있습니다. Depthwise Separable Convolution의 설명과 computational cost계산법은 추후에 다른 게시글에서 소개하도록 하겠습니다.
이러한 연산 방법이 가능한 이유로는 Xception의 핵심가설인 The mapping of cross-channels correlation and spatial correlation can be entirely decoupled을 살펴보게 되면
- cross-channels correlation: conv층에 입력되는 이미지들의 유사한 정도
- spatial correlation: conv 필터와 입력 채널 사이의 상관도, 필터가 이미지의 특성을 잘 포착하는 정도
이 두가지가 서로 독립적으로 보기 때문에, 결국 입력 채널을 변형(압축)해서 넣어도 성능에 크게 영향이 없다는 것으로 해석할 수 있습니다.
3.2 Linear Bottlenecks
먼저 두가지를 가정하고 시작합니다. manifolds of interest는 low-dimensial subspaces로 맵핑이 가능하다. 그리고 비공식적이지만 real image input을 받았을 때 layer들이 manifold of interest을 형성한다. 이 두 가지를 가정하고 보면 ReLU를 통과한 후에 manifold of interest가 non-zero volume을 가지면 linear 한 구조로 되어있다. 그리고 input manifold가 low-dimensianal subspace에 살고 있다.라는 결론을 통해서 linear bottleneck layer을 쓰면 효과적이다 라는 최종 결론이 나옵니다.
실험을 통한 결과를 보면 linear layer을 사용하는 것이 비선형성이 너무 많은 정보를 파괴하는 것을 방지합니다.
지금까지 글은 논문에 있는 글을 나름 해석하면서 정리한 것이고 한번 더 간단하게 정리해보겠습니다. 이 manifold 가설은 고차원의 정보는 사실 저 차원으로 표현이 가능하다는 것입니다. 예를 들자면 3d를 2d로 나타내도 사람 눈으로 구별하는 것처럼 말입니다. 그리고 또 중요한 것은 ReLU를 무작정 사용하면 정보 손실이 있을 수 있다는 겁니다. 다시 말하자면 고차원일 때는 크게 문제없지만 저차 원일 때 ReLU를 사용하게 되면 정보 손실이 많아집니다.

위에 그림을 보시게되면 차원을 2,3,4,15,30을 각각 쓰고 ReLU를 거친 후 복원한 데이터들입니다. 15,30 경우에는 나름 데이터가 잘 복원된 것을 확인할 수 있지만 저차원 일 때는 데이터가 많이 손실된다는 사실을 알 수 있습니다.
따라서 Linear Bottlenecks에서는 ReLU를 사용하지 않고 linear bottleneck layer을 사용합니다.
3.3Inverted residuals

bottlenecks이 실제로는 필요한 모든 정보를 포함하고 있다는 영감에서 시작됩니다. 그래서 narrow -> wide -> narrow의 block을 활용해서 메모리 사용량에서 효율을 가져올 수 있다고 주장합니다.
따라서 정리해보면 기존의 bottleneck(c)는 wide -> narrow -> wide 방식이지만 Inverted Residual(d)는 narrow -> wide -> narrow방식입니다. input data와 output data의 크기가 작기 때문에 메모리에 효율적이라고 주장하는 겁니다.
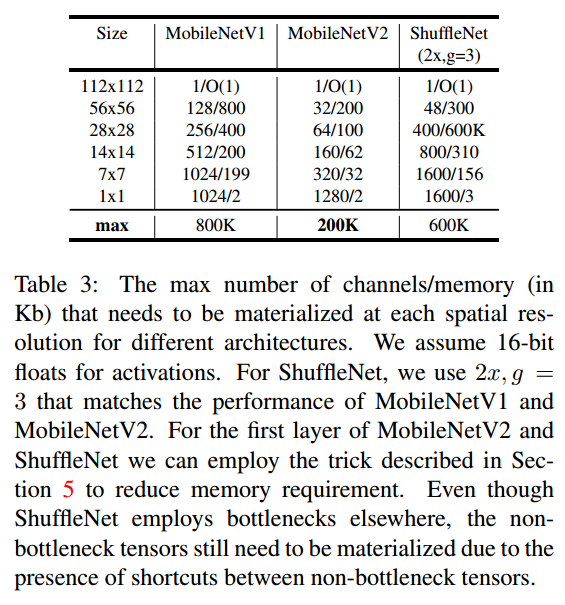
다음 표를 통해서도 input/output의 dimenstion이 작기 때문에 상대적으로 memory requirement가 다른 모델에 비해 작은 것을 알 수 있습니다.
3.4 Information flow interpretation
이 아키텍쳐에서 흥미로운 부분은 input/output 영역과 transformation 영역(input을 output으로 바꿔주는 비선형함수)이 나누어져 있다는 것입니다. input/out여역은 capacity부분이라 할 수 있고 transformation 영역은 expressiveness부분이라고 칭할 수 있습니다. 이것은 기존의 convolution 이 capacity와 expressiveness가 서로 합쳐져 있는 것으로 비해 대조적이라고 할 수 있습니다.
4.Model Architecture
다음 표는 전체적인 mobilenetV2의 아키텍처입니다.

t: block내부에서 팽창시킬 배수 (block내부 채널 수 = t*c)
c: 채널 수
n: bottleneck의 반복 수
s: stride

stride가 1일 때는 shorcut을 사용하고 stirde가 2 일때는 shortcut을 사용하지 않습니다. 여기에 대한 이유는 논문에서 찾아볼 수 없었지만 제가 추측했을 때는 stride 2를 적용하면서 크기가 줄어드는데 크기가 줄어들 때 shortcut을 사용하면 선형성이 보장되지 않기 때문이라고 추측합니다.
또 다른 특징으로는 ReLU6을 사용하였다는 건데, 이는 기존 ReLU의 x>0의 구간에서 x가 6보다 클 때는 6으로 하는 함수입니다. 이를 사용한 이유는 low precision을 사용하기 때문이라고 합니다.
mobilenetV2 의 inverted residual bottleneck block을 잘 표현한 그림이 있어서 가져와봅니다.


다음 그림들을 보시면 좀 더 이해하기 쉬울 것입니다.
5.Implementation Notes
6.Experiments
여기서는 소제목 그대로 실험한 결과들에 대해서 적어놓았습니다. 실험 환경에 대한 소개 파라미터 값 등에 대해서 알려주고 MobilenetV1, ShuffleNet, NASNet-A와 비교해서 결과를 소개했습니다. 읽어보시면 당연히 mobilenetV2가 제일 좋다 라는 결과들이 적혀있습니다.

7.Conclustions and future work
우리는 간단한 아키텍처에 대해서 소개했다... 이미지 넷 데이터셋을 대상으로 우리 아키텍처는 광범위한 성능 포인트에 대한 최첨단 기술을 개선한다... 객채 탐지 부분에서도 coco데이터셋 기반으로 했을 때 성능이 뛰어나다... 특히 ssdlite와 결합했을 때 YoLoV2보다 적은 매개 변수와 적은 계산양을 가지고 있다 등 mobilenet_v2가 좋다는 것을 어필하고 있습니다. 그리고 연구 방향으로는 capacity와 expressiveness를 네트워크에서 분리할 수 있는데 이는 향후 연구를 위한 좋은 방향이라고 서술합니다.
후기
mobilenetV2를 직접 사용할 일이 있어서 논문을 읽어보고 공부하면서 전체적으로 정리를 해봤습니다. 분명 틀린 부분도 있을 거고 여러모로 많이 부족할 겁니다 ㅜㅜ 그래도 꾸준히 여러 논문을 읽어보면서 발전해나가도록 해보겠습니다.
이상으로 mobilenetV2: Inverted Residuals and Linear Bottlenecks 논문 리뷰를 마치도록 하겠습니다.
지금까지 읽어주셔서 감사합니다!
'AI' 카테고리의 다른 글
| Distance-IOU Loss (DIOU) 논문 리뷰 (0) | 2021.07.12 |
|---|---|
| 오차역전파-1 (딥러닝) 곱셉노드, 덧셈노드 (0) | 2021.06.20 |
| CUDA Toolkit 삭제 & 다운(11.2 -> 11.1) (0) | 2021.03.23 |
| 딥러닝에서 필터의 개수는 왜 증가할까 (0) | 2021.01.27 |
| Classification 성능 올리는 법 (0) | 2021.01.22 |